本文作者:李丹(dan)
来源:硬(ying)AI
不到两(liang)周(zhou)后,我们可能就会见到迄今为止最强大(da)的开源Llama 3模型。
美东(dong)时间7月12日周(zhou)五,媒体援引一名Meta Platforms的员工消息(xi)称,Meta计划7月23日发(fa)布旗下第三代(dai)大(da)语言模型(LLM)Llama 3的最大(da)版本。这一最新版模型将拥有4050亿参数,也将是多(duo)模态模型,这意味着它将能够理解和生成图像和文本。该媒体未透露这一最强版本是否(fou)开源。
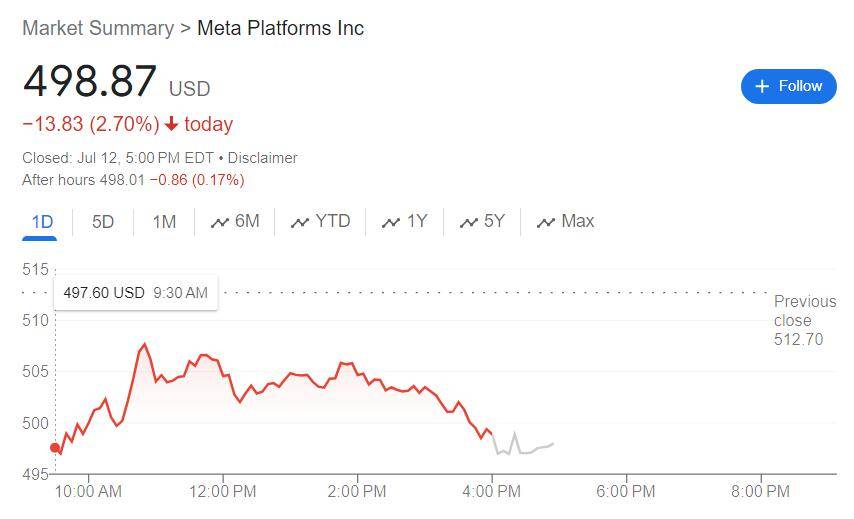
Meta公司拒绝对上(shang)述消息(xi)置评。周(zhou)五盘中,低开的Meta股价跌幅收窄,盘初曾跌3.6%,此后跌幅曾收窄到不足2%,但(dan)尾盘跌幅扩大(da),收跌2.7%,在周(zhou)四(si)大(da)幅回落超4%后连跌两(liang)日,刷新6月21日以来收盘低位(wei)。
去年7月Meta发(fa)布的Llama 2有三个版本,最大(da)版本70B的参数规模为700亿。今年4月,Meta发(fa)布Llama 3Meta,称它为“迄今为止能力最强的开源LLM”。当时推(tui)出的Llama 3有8B和70B两(liang)个版本。
Meta CEO扎克(ke)伯格当时称,大(da)版本的Llama 3将有超过4000亿参数。Meta并未透露会不会将4000亿参数规模的Llama 3开源,当时它还在接受训练(lian)。
对比前代(dai),Llama 3有了质的飞跃。Llama 2使用2万亿个 token进行训练(lian),而训练(lian)Llama 3大(da)版本的token超过15 万亿。
Meta称,由于预训练(lian)和训练(lian)后的改进,其预训练(lian)和指令调优的模型是目前8B和70B两(liang)个参数规模的最佳模型。在训练(lian)后程序得到改进后,模型的错误拒绝率(FRR)大(da)幅下降,一致性提高,模型响应的多(duo)样性增加。 在推(tui)理、代(dai)码生成和指令跟踪等功能方面,Llama 3相比Llama 2有极(ji)大(da)改进,使Llama 3更易(yi)于操控。
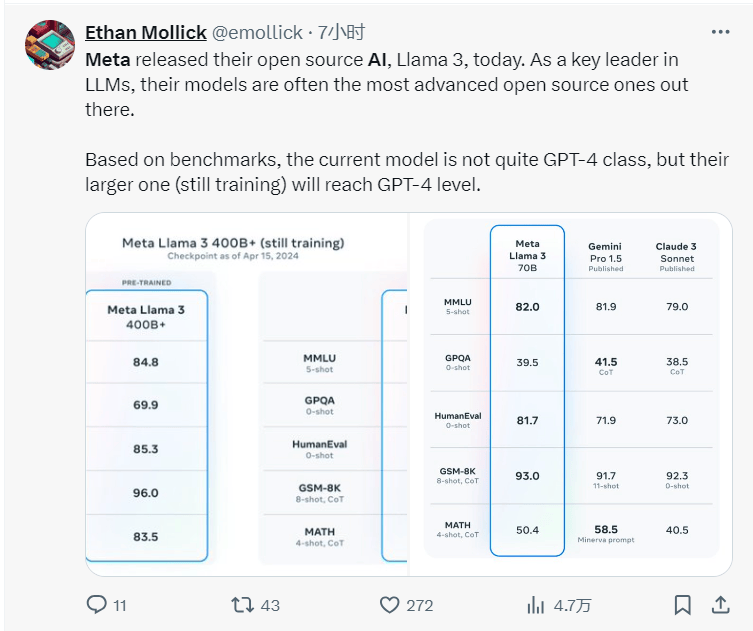
4月Meta展示,8B和70B版本的Llama 3指令调优模型在大(da)规模多(duo)任务语言理解数据集(MMLU)、研(yan)究生水平专家推(tui)理(GPQA)、数学评测集(GSM8K)、编程多(duo)语言测试(HumanEval)等方面的测评得分(fen)都高于Mistral、谷歌的Gemma和Gemini和Anthropic的Claude 3。8B和70B版本的预训练(lian)Llama 3多(duo)种性能测评优于Mistral、Gemma、Gemini和Mixtral。
当时社交媒体的网(wang)友评论称,根据基准测试,当前的Llama 3模型不完全是 GPT-4 级别的,但(dan)仍在训练(lian)中的较(jiao)大(da)尺寸的模型将达(da)到 GPT-4 级别。
英伟达(da)高级科学家Jim Fan认为,Llama 3的推(tui)出已经脱离了技术层面的进步,更是开源模型与顶尖(jian)闭源模型可分(fen)庭抗礼的象征。
从Jim Fan分(fen)享的基准测试可以看出,Llama 3 400B 的实力几乎(hu)媲美 Claude“超大(da)杯”以及新版 GPT-4 Turbo,将成为“分(fen)水岭”,相信它将释放巨大(da)的研(yan)究潜力,推(tui)动整个生态系统(tong)的发(fa)展,开源社区或将能用上(shang)GPT-4级别的模型。
此后有消息(xi)称,研(yan)究人员尚未开始对Llama 3进行微调,还未决(jue)定Llama 3是否(fou)将是多(duo)模态模型;正式版的Llama 3将会在今年7月正式推(tui)出。
不同(tong)于OpenAI等开发(fa)商,Meta致力于开源LLM,不过,这个赛道也越来越拥挤。谷歌、特斯拉CEO马斯克(ke)旗下的xAI和Mistral 等竞争(zheng)对手也发(fa)布了免费的AI模型。
Llama 3问(wen)世后,同(tong)在4月亮相的4800亿参数模型Arctic击败Llama 3、Mixtra,刷新了全球最大(da)开源模型的纪录。
Arctic基于全新的Dense-MoE架构设(she)计,由一个10B的稠密Tranformer模型和128×3.66B的MoE MLP组(zu)成,并在3.5万亿个token上(shang)进行了训练(lian)。相比Llama 3 8B和Llama 2 70B,Arctic所用的训练(lian)计算资源不到它们的一半,评估(gu)指标却取得了相当的分(fen)数。